Async Rust can be a pleasure to work with (without `Send + Sync + 'static`)
Async Rust is powerful. And it can be a pain to work with (and learn). If you’ve used async Rust, you’ve almost certainly run into the need to add Send + Sync + ‘static bounds to functions, wrap variables in Arcs and Mutexes, clone those Arcs all over the place, and you've inevitably hit the "future is not Send" error when you forget an Arc::clone.
Async Rust can be a pleasure to work with, though, if we can do it without Send + Sync + 'static. How? Through a combination of Structured Concurrency and thread-per-core async runtimes.
Async without 'static
Why do futures need to be 'static anyway? The answer is how futures are often run in Rust; specifically, with a spawn function. This is the signature for tokio::spawn (notice those 'static bounds):
pub fn spawn<F>(future: F) -> JoinHandle<F::Output>
where
F: Future + Send + 'static,
F::Output: Send + 'static,
spawn needs 'static bounds because we are scheduling that future to be run in the background. The future outlives the scope of the function that invokes it so the borrow checker can't help us statically determine when the values it contains can be cleaned up. 'static tells the borrow checker that, as far as it is concerned, those values will live forever.
The 'static bound is why we need reference-counted pointers like Arcs. We're replacing what would be a compile-time decision about when values can be dropped with a runtime check.
Some of the pain we feel when writing async Rust today comes from the fact that we're circumventing one of the core parts of Rust (using lifetimes and the drop checker for automatic cleanup) and going against the natural "grain" of the language. It's not the same as unsafe, but with 'static we are turning off a core part of the language -- and the result is painful.
Can we run futures without the need for 'static bounds? Yes! Async runtimes like tokio all come with a Runtime::block_on method. This is the signature of the function in tokio (notice the lack of 'static bounds):
pub fn block_on<F: Future>(&self, future: F) -> F::Output
Okay, but that only runs a single future, right? The whole point of async is to handle multiple tasks concurrently. Right. This is where we take a little foray into the arguably under-appreciated concept of Structured Concurrency.
Structured Concurrency
Structured concurrency is an incredibly simple idea with profound implications. Put simply, every future should be created within a scope, and that scope is only finished once every future it contains is finished. In contrast, unstructured concurrency refers to the ability to spawn tasks in the background such that their execution is disconnected from the context where they are created.
In Tree-Structured Concurrency, Yoshua Wuyts describes it this way:
Structured concurrency is a property of your program. It's not just any structure, the structure of the program is guaranteed to be a tree regardless of how much concurrency is going on internally. A good way to think about it is that if you could plot the live call-graph of your program as a series of relationships it would neatly form a tree. No cycles. No dangling nodes. Just a single tree.
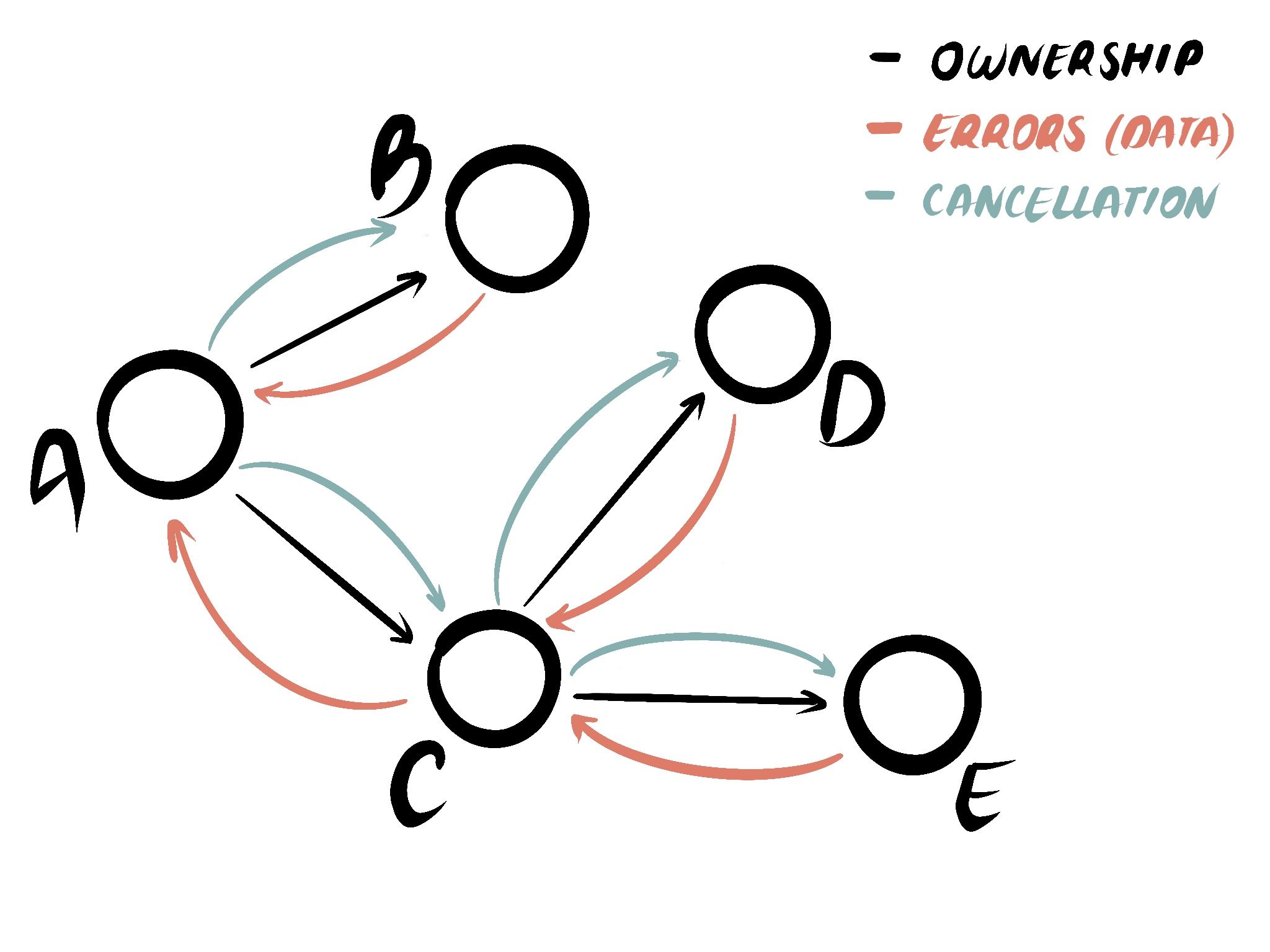
Credit to Yoshua Wuyts for this diagram.
Some of the main benefits of structured concurrency, as outlined by the excellent and provocative essay Notes on structured concurrency, or: Go statement considered harmful (which I would recommend reading in full) are:
- Maintaining function abstractions as black boxes - when a function completes, you know that it is done. In contrast, if functions are capable of spawning background tasks, you need to actually read their source code (breaking the black box abstraction) to figure out if they are actually done when they exit.
- Propagating errors automatically - errors created in sub-tasks naturally propagate up through the scope. When tasks are spawned in the background, errors are swallowed silently by default unless you manually add error handling.
- Enabling automatic resource cleanup - when a scope completes, all of the resources (such as variables, files, or database connections) used by tasks spawned within it can be cleaned up automatically. In contrast, when tasks are run in the background, it becomes much less obvious when resources can be cleaned up.
This last point was the one that triggered the aha! moment for me when thinking about async Rust. Rust's lifetimes and drop checker are all about automatic resource cleanup. The compiler statically analyzes programs to determine when values can be dropped.
Unstructured concurrency makes it impossible for the compiler to automatically clean up for us. We need 'static to circumvent the normal lifetime behavior and drop checker and then we need reference-counted pointers to implement cleanup at runtime. If futures are instead bound to a scope, their lifetimes are also naturally bound to that scope's lifetime and the borrow checker can properly determine when resources should be dropped.
Structured Concurrency in Rust
The main primitive for unstructured concurrency in Rust is tokio::spawn (or the spawn function of another runtime) -- and that's what we want to avoid using.
There are a number of different ways to use structured concurrency in Rust. I would argue that we could group them into two categories: dynamic and static. In the "dynamic" or heap-allocated style, we can spawn futures where we do not know the exact number at compile-time. In the "static" or stack-allocated style, we must know the exact number of futures at compile-time -- and we would expect better performance as a result. (Thanks to matklad for pointing out the two different styles, based on a conversation he had with withoutboats.)
Dynamic Structured Concurrency
Dynamic structured concurrency lends itself well to cases where we cannot know the exact number of futures at compile-time. For example, when we have futures that handle incoming connections.
The crates I know of that provide functionality for dynamic structured concurrency are moro, futures-concurrency (specifically the FutureGroup), async_nursery, and FuturesUnordered (which moro uses under the hood).
In moro, you create an async Scope and you spawn futures into that scope:
#[tokio::main]
pub async fn main() {
let listener = TcpListener::bind("127.0.0.1:8080").await?;
moro::async_scope!(|scope| {
loop {
let (socket, _) = listener.accept().await?;
scope.spawn(process_socket(socket));
}
}).await;
}
The example above doesn't directly illustrate the ability to work without the 'static lifetime, but the example below shows how you can use moro to spawn futures that access values that outlive the scope and access values that are not wrapped in Arcs.
#[tokio::main]
pub async fn main() {
let value = RwLock::new(22);
moro::async_scope!(|scope| {
scope.spawn(async {
// we can spawn nested tasks
scope.spawn(async {
// and access values that outlive the scope
*value.write().unwrap() *= 2;
});
*value.write().unwrap() *= 2;
});
})
.await;
let result = *value.read().unwrap();
println!("{result:?}"); // prints 88
}
By spawning futures within the scope, we're tying the lifetime of those futures to the scope and therefore don't need the 'static bound. As a result, we can use async without reference counted pointers and we can avoid all of those Arc::clones!
Static Structured Concurrency
The unique design of Rust's futures also makes static structured concurrency possible. withoutboats talks about this while describing "intra-task concurrency":
the fact that you can select a variety of futures of different types and await whichever of them finishes first & from within a single task, without additional allocations, is a unique property of async Rust compared to non-async Rust & one of it’s most powerful features.
Some of the main static structured concurrency primitives I know of include futures::join, futures::select, as well as others implemented in futures-concurrency.
For example, if you are making asynchronous calls to multiple external services, you could write something like:
#[tokio::main]
pub async fn main() {
let image = storage::load_profile_image(user.id);
let profile = db::load_profile(user.id);
let (image, profile) = futures::try_join!(image, profile).await?;
}
This approach does not require any heap allocations and will be more performant in any case where the number of futures is known at compile-time.
The dynamic and static approaches to structured concurrency will vary in terms of their performance and ideal use cases, but both enable us to work with futures without the 'static lifetimes. Structured concurrency enables resources to be automatically cleaned up by the drop checker once the async scope or merged future is finished. It also means that errors bubble up naturally, and we can preserve the function black box abstraction because we know that when an async function is finished it is really finished.
Async without Send + Sync
Now that we've seen that we can avoid the 'static lifetime using structured concurrency, let's turn our attention to Send and Sync.
Send means that a value can safely be moved between threads. Most types automatically implement Send except references, Rcs, and any value that contains one of these. (This is why you end up with the "future is not Send error if you capture a reference, as opposed to moving an owned value into an async move block.) Sync is a stricter bound that means a type cannot only be sent between threads but is also safe to modify from share between multiple threads. Mutexes and RwLocks provide Sync access to values that wouldn't be safe to modify from multiple threads in parallel.
Correction:
Syncis about sharing values between threads, not necessarily about mutating them. It is very uncommon for futures to need to beSync, but any kind of state that is shared between futures needs to beSync.Mutexes andRwLocksprovide mutable access to values shared between threads.
What do Send and Sync have to do with async Rust? Actually, they are only needed because tokio, the most popular async runtime, is a multi-threaded, work-stealing runtime. If you call tokio::Runtime::block_on you don't need the future to be Send, but you do as soon as you start spawning futures. This is because those tasks might be moved at any time between threads. (In other words, while Concurrency is not parallelism, most async Rust today mixes the two by default.)
The Send bound is the source of one of the biggest complaints about async Rust. This raises the question: do we (always) need a multi-threaded, work-stealing runtime?
Thread-per-core
The main alternative to a work-stealing runtime is commonly referred to as "thread-per-core". (In Local Async Executors and Why They Should be the Default, Maciej Hirsz made the case that this pattern should be the default way of doing async Rust.) Instead of having multiple threads that automatically steal work from one another when they are unoccupied, a thread-per-core architecture involves keeping work tied to a specific thread.
In Rust, some alternative runtimes that lend themselves to thread-per-core architectures are glommio from DataDog and monoio from ByteDance, as well as the experimental tokio-uring. These three all achieve high performance using io_uring, which is a Linux kernel API that enables high throughput by batching system calls and avoiding jumps between user space and kernel space. io_uring, though, requires a single thread to own the ring buffers that give the feature its name, which lends itself to use with single-threaded async runtimes. Aside from runtimes that use io_uring, embedded runtimes like Embassy are also single-threaded.
Why does single-threaded / thread-per-core / share-nothing matter? All of these assume that futures will be handled by the thread that created them, which in turn removes the need for the Send bound. Without the Send bound, we can write async Rust without Mutexes, RwLocks, and without constantly cloning reference-counted pointers. (We can even avoid the need for move closures and async move blocks because non-Send futures don't need to own the values they capture.)
The architectural shift to thread-per-core can not only simplify the developer experience, but it can also be used to achieve extremely high performance. A notable example of this, though it's not written in Rust, is TigerBeetle (disclaimer: I contracted with them for a few months). It's a high-performance database built for business transactions that is single-threaded by design -- and it uses io_uring. The single-threaded design actually improves the performance for TigerBeetle's use case because it circumvents the need for row locks in transactions, which can grind the performance to halt for hot accounts. Not all use cases would see increased performance from a single-threaded design, but the paper Scalability! But at what COST? suggests that single-threaded implementations may perform better than parallelized ones for many more algorithms than people might commonly think.
The spectrum from share-nothing to work-stealing
withoutboats argues that it would be more precise to refer to the "thread-per-core" architecture as a "share nothing" architecture, because runtimes like Tokio do create a thread per core and then share the work between those threads. This is a fair critique of the terminology, and I think it's worth thinking about a spectrum from share-nothing to work-stealing.
Share-nothing means that no resources, no files, no database connections, no state, and no tasks are shared between any of the worker threads. On the opposite end of the spectrum, work-stealing means that every resource can be shared between any of the threads -- and, importantly, those may be moved at any time between the threads.
There is arguably an under-explored middle ground between work-stealing and share-nothing.
Let's imagine a multi-threaded system, where each thread is running its own async runtime such as glommio or Tokio's current thread runtime. We might have some resources that we want the threads to share, such as a database connection pool or an incoming connection queue. Can we share this state across our threads without making absolutely everything Send? Yes!
The subtle distinction is that any resources that are shared between the threads definitely need to be Send (and Sync if they are mutable), but our futures themselves don't necessarily need to be Send. If each Future is pinned to a single thread, we can still operate without Send + Sync + 'static -- while sharing some things between threads.
Granularity of load balancing
What we're really getting at here is the granularity of work that we want to share or load balance between threads.
Work-stealing makes it possible to load balance at every await point in a future.
In contrast, we could load balance at the level of each incoming connection without needing our futures to be Send. Once a connection is assigned to a thread, it would stay there. If that connection requires more work than others, we should be able to assign subsequent incoming connections to other threads but we wouldn't move tasks that have already been started.
What is the right level of granularity for load balancing? Honestly, I'm not sure.
However, for things like web servers, we are probably already running multiple instances and load balancing between them (for reasons other than scale). Do we need every instance to be multi-threaded and load balancing internally, or load balancing at every await point?
Arguing for work-stealing, withoutboats wrote:
A problem that emerges in real systems is that different tasks end up requiring different amounts of work. For example, one HTTP request may require far more work to serve than another HTTP request. As a result, even if you try to balance work up front among your different threads, they can each end up performing different amounts of work because of unpredictable differences between the tasks.
Under maximum load, this means that some threads will be scheduled more work than they can perform, while other threads will sit idle. The degree to which this is a problem depends on the degree to which the amount of work performed by different tasks differs.
This alludes to a question where it seems we need more data: to what extent does the work performed by different tasks differ in practice or for specific systems? Remember that this work does not include time only spent waiting for something like a database transaction to complete.
I would guess that for most API servers handling HTTP requests or RPC commands, each request would require relatively similar amounts of CPU time. And, I would guess that the amounts of work done by each request is a small fraction of the work incurred by all of the requests. If that's the case, balancing work upfront by distributing requests or tasks among the threads seems like it would lead to a relatively balanced system. (Websockets or other long-lived connections might be a different story, though, because you don't know how long a connection will last when it is initially received.)
The Tokio blog post that explains its work-stealing scheduler actually says:
A key thing to remember about the work-stealing use case is that, under load, there is almost no contention on the queues since each processor only accesses its own queue.
If that's the case, it would raise the question of how often work is actually stolen in servers under load.
In Tasks are the wrong abstraction, Yoshua Wuyts writes:
The premise of work-stealing is that the performance gains it provides are more than the performance penalties we incur from requiring all futures are
Send. Because making futuresSendnot only carries a degree of complexity for the language, it also comes with inherent performance penalties because it requires synchronization. You know how you can't useRcwithasync/.await- that's a direct artifact of work-stealing designs.
Benchmarking work-stealing and thread-per-core
I am no benchmarking expert -- and of course, benchmarks always need the disclaimer that real-world performance is highly dependent on the specific workload. But I wanted to try to compare the performance of Tokio with a thread-per-core runtime like Glommio.
Below are my results (code is here). This is running a simple HTTP server serving small ("Hello, world!") GET requests on a Dedicated CPU Linode machine with 16 CPUs and 32 GB of RAM. The load generation ran on the same server using wrk running for 2 minutes with 8 threads keeping 800 concurrent connections (100 per thread) open.
| Runtime + HTTP framework | Num Threads | Throughput (Requests / Sec) | 50th Percentile Latency (ms) | 99th Percentile Latency (ms) | Max (ms) |
|---|---|---|---|---|---|
| Tokio + Hyper | 1 | 92,543.69 | 8.40 | 16.6 | 26.16 |
| Tokio Work Stealing* + Hyper | 8 | 597,472.31 | 1.29 | 2.93 | 52.97 |
| Tokio Round Robin* + Hyper | 8 | 588,788.43 | 1.30 | 2.84 | 66.26 |
| Glommio + Hyper | 1 | 92,700.52 | 8.41 | 10.55 | 46.96 |
| Glommio + Hyper | 8 | 678,234.99 | 1.13 | 4.12 | 40.49 |
| NGINX | 1 | 35,867.86 | 22.33 | 29.44 | 51.88 |
| NGINX | 8 | 187,840.20 | 4.12 | 10.31 | 29.82 |
* The "Tokio Work Stealing" row shows Tokio's normal multi-threaded runtime. The "Tokio Round Robin" compares it to a simple wrapper that uses one thread to accept incoming TCP connections and then passes them off to a worker thread (one less than the number of threads) using a simple round-robin technique. This latter method still uses Tokio but removes work-stealing so that it works with non-
Sendfutures.
You can see that the Glommio throughput slightly surpasses Tokio (13% higher), the 50th percentile latency is slightly lower (14% lower), and the 99th percentile latency is higher (40% higher). I also included NGINX for comparison (and both the Tokio and Glommio servers beat it by a significant multiple -- which also means that all of this extra performance is for naught if you put your Rust servers behind NGINX).
The benchmark above uses very small and homogeneous tasks, which means that we would expect Tokio's work-stealing scheduler not to show its full benefit.
In the benchmark below, I modified the HTTP service such that it awaits a random number of futures between 0 and 10 (inclusive) and where each future synchronously sleeps for 10 microseconds (so each request takes between 0 and 100 microseconds total). The idea here is to simulate the request handler awaiting additional futures, each of which requires some CPU time.
| Runtime + HTTP framework | Num Threads | Throughput (Requests / Sec) | 50th Percentile Latency (ms) | 99th Percentile Latency (ms) | Max (ms) |
|---|---|---|---|---|---|
| Tokio + Hyper | 1 | 2,909.87 | 266.71 | 515.79 | 566.40 |
| Tokio Work Stealing + Hyper | 8 | 21,986.46 | 34.67 | 86.81 | 148.90 |
| Tokio Round Robin + Hyper | 8 | 19,329.83 | 40.16 | 81.97 | 835.27 |
| Glommio + Hyper | 1 | 2,873.93 | 278.00 | 295.52 | 309.80 |
| Glommio + Hyper | 8 | 21,674.20 | 36.33 | 43.03 | 62.34 |
In this test, both Tokio and Glommio had similar throughputs and 50th percentile latencies. Surprisingly, Glommio actually beat Tokio in terms of 99th percentile latency (51% lower) and max latency (59% lower). Theoretically, the purpose of work-stealing is to reduce the tail latency for tasks with varying amounts of work -- so it's possible that some different benchmark would better approximate such a workload.
Some additional caveats:
- A thread-per-core runtime like Glommio might perform even better with a different HTTP framework that focuses on zero-copy data handling.
- There are different polling modes that
io_uringcan operate in. While this paper is focused on disk I/O rather than network I/O, it suggests that the polling strategy may have a significant impact on performance. Unfortunately, Glommio does not allow you to tweak this setting.
The core argument of this blog post is more focused on developer experience than performance, but we want to know that we are either not sacrificing too much performance or are ideally gaining some performance by foregoing work-stealing. Benchmarks are complicated and I would shy away from relying on them too heavily. However, I think the takeaway from these tests is that it seems possible to achieve similar performance with Tokio and a thread-per-core runtime, at least for workloads like these.
Async without Send + Sync + 'static
Now that we've talked about how we can use async Rust without Send + Sync + 'static, what does it look like to develop with?
Here we have an (admittedly contrived) example of some async code using Tokio's multi-threaded runtime. It includes awaiting values from a stream, spawning a dynamic number of background tasks, and joining the results of two futures. Note how every part of the Context is wrapped in Arcs so that we can clone them before passing those fields into the async move blocks (and we do this pretty frequently).
#[derive(Default, Clone)]
struct Context {
db: Arc<Database>,
service_a: Arc<ServiceA>,
service_b: Arc<ServiceB>,
service_c: Arc<ServiceC>,
}
#[tokio::main]
pub async fn main() -> Result<(), ()> {
let context = Context::default();
while let Some(request) = incoming_requests().next().await {
let context = context.clone();
tokio::spawn(async move {
let request = Arc::new(request);
let some_things = context.db.load_things().await?;
for thing in some_things {
let service_a = context.service_a.clone();
let request = request.clone();
tokio::spawn(async move {
if let Err(err) = service_a.do_something(&request, thing).await {
eprintln!("What do we do with this error? {:?}", err);
}
});
}
let request_clone = request.clone();
let service_b = context.service_b.clone();
let result_b =
tokio::spawn(async move { service_b.do_something_else(&request_clone).await });
let service_c = context.service_c.clone();
let result_c =
tokio::spawn(async move { service_c.do_something_else_else(&request).await });
let (b, c) = tokio::try_join!(result_b, result_c).map_err(|_| ())?;
Ok::<_, ()>(Response { b: b?, c: c? })
});
}
Ok(())
}
Now here is the equivalent code using Tokio's current thread runtime (to emulate thread-per-core). It uses the async_scope macro from moro-local, which is my fork of moro that works on stable Rust and is designed for non-Send futures. Note how the fields in the Context struct don't need to be wrapped in Arcs and note the lack of async move blocks and all of the clones that we needed in the previous version.
#[derive(Default)]
struct Context {
db: Database,
service_a: ServiceA,
service_b: ServiceB,
service_c: ServiceC,
}
#[tokio::main(flavor = "current_thread")]
pub async fn main() -> Result<(), ()> {
let context = Context::default();
moro_local::async_scope!(|scope| {
while let Some(request) = incoming_requests().next().await {
scope.spawn(async {
let request = request;
moro_local::async_scope!(|scope| {
let some_things = context.db.load_things().await?;
for thing in some_things {
scope.spawn(async { context.service_a.do_something(&request, thing) });
}
let result_b = context.service_b.do_something_else(&request);
let result_c = context.service_c.do_something_else_else(&request);
let (b, c) = futures::try_join!(result_b, result_c).map_err(|_| ())?;
Ok::<_, ()>(Response { b, c })
})
.await
});
}
})
.await;
Ok(())
}
Obviously, this code is a bit contrived. However, it is meant to succinctly demonstrate multiple patterns that I have seen in real async Rust codebases. By using structured concurrency and a thread-per-core runtime, we can use normal references, lifetimes work as expected, and we can forego the need to wrap everything in Arcs and clone everything before passing values into async blocks.
Are we thread-per-core web yet?
Unfortunately not. It is possible to use hyper without the Send + 'static bounds (see the single-threaded example). However, all most of the most popular higher-level web frameworks like axum, actix-webpoem, and tide require handlers to be Send + 'static. (xitca-web is a newer web framework focused on zero-copy request handling, which lends itself to thread-per-core architectures and use with non-Send Futures. It may be worth keeping an eye on.)
Correction:
actix-webandntexsupport handlers that return non-Send + 'staticfutures.
This state of affairs is closely related to the Async trait send bounds that Niko Matsakis described in a series of blog posts. Since there isn't a way for users to specify whether or not async methods in traits return futures that implement Send, the authors of libraries default to stipulating that they must be Send + 'static. It would be nice if web frameworks provided support for both Send and non-Send HTTP handlers, but at present this would require a fair amount of code duplication.
So, if you're willing to write your async code directly on top of an async runtime or a lower-level HTTP library like hyper, you can write it without Send + Sync + 'static bounds today. If not, you might need to wait for web framework support for non-Send + 'static futures.
As a community, I think we should put more work into writing libraries and frameworks that support thread-per-core runtimes and non-Send + 'static futures. The current paradigm where everything in async Rust must be Send + 'static is hard for new users, tedious for experienced developers, and I think there reasonable reasons to question the assumption that work-stealing necessarily means better performance.
Conclusion
I originally intended to write a macro that automatically clones and shadows Arc'ed values before they're moved into async move blocks and move closures (similar to enclose, but where it would automatically figure out which variables to clone). However, I came across the structured concurrency blog post, which made me wonder whether the annoyances of working with 'static lifetimes and constantly cloning Arcs are actually indicative that we're doing something "wrong" -- or at least suboptimal.
There is a longstanding discussion in the Rust community about "scoped tasks". Two particularly good posts that lay out the problem space are withoutboats' The Scoped Task trilemma and Tyler Mandry's A formulation for scoped tasks in Rust. withoutboats writes:
Any sound API can only provide at most two of the following three desirable properties:
- Concurrency: Child tasks proceed concurrently with the parent.
- Parallelizability: Child tasks can be made to proceed in parallel with the parent.
- Borrowing: Child tasks can borrow data from the parent without synchronization.
This blog post argues for more focus on the "Borrowing + Concurrency" resolution of the trilemma, or "Relaxing Parallelism" as Tyler Mandry put it. Given the emergence of thread-per-core runtimes and io_uring, it is worth re-examining whether we really need our futures to be movable between threads at every await point.
I think the Parity developer tomaka put it well when they wrote:
There is nothing wrong per se in putting everything in an
Arc. The problem is that… it almost doesn’t feel like you’re writing Rust anymore.The same language that encourages you to pass data by references, for instance
&strinstead ofString, also encourages you to split up your code into small tasks that have to clone every piece of data they send to one another. The same language that provides a complex lifetimes system to avoid the need for a garbage collector now also encourages you to put everything in anArc.I don’t think that this is really a problem, but I do feel like there are now two languages into one: a lower-level language for CPU-only operations, that uses references and precisely tracks ownership of everything, and a higher-level language for I/O, that solves every problem by cloning data or putting it in
Arcs.
We can write async Rust that feels more similar to synchronous Rust if we can do without both the Send and 'static requirements. We can remove the Send bounds by using thread-per-core runtimes and we can do without 'static by replacing calls to spawn with structured concurrency primitives like moro::async_scope or others from futures-concurrency.
Async Rust is considerably more pleasant to write today than in the pre-async/await days of manually chained futures. Removing the Send + 'static bounds would remove a major stumbling block for new developers and recurring paper cuts for more experienced Rustaceans.
Future work
If the ideas explored in this post resonated with you, here are some things that might be worth digging into more:
- The Ergonomic Ref Counting proposal was accepted into the Rust project's goals for the 2nd half of 2024, which means that something should be added to Nightly within the next 6 months to remove the need to explicitly clone
Arcs when moving them into closures and futures. This would remove some of the pain of working withSend + 'staticfutures so it's worth keeping an eye on this work. - We could use more benchmarking and real-world data about the performance of work-stealing in practice and with different workloads.
- We could also use more exploration of the performance of thread-per-core runtimes using
io_uringalong with structured concurrency and zero-copy designs. - It would be very nice if higher-level libraries like web frameworks did not enforce the
Send + 'staticbounds, unless they directly callspawn. Ideally, theSend + 'staticbounds would come from how the server is run (e.g. withtokio::spawn) rather than being enforced by the framework's own traits. - Thread-per-core runtimes like
glommiomight want to more heavily encourage the use of structured concurrency overspawnstyle APIs so users can do without the'staticlifetimes. - When using a thread-per-core runtime, it might be interesting to have an option to explicitly run a background task such that any worker thread could pick it up. This could be another interesting middle ground between share-nothing and work-stealing where users could intentionally spawn
Send + 'statictasks onto a global work queue, without making all futuresSend + 'staticby default. - The posts What If We Pretended That a Task = Thread? and Non-Send Futures When? explore an interesting question about whether the need for
Sendbounds could be removed by redefiningSendto refer to an "execution context" rather than a specific thread (such that that execution context would more with the task). This would be great, but I'm approaching this topic from the perspective of a user of the language as it exists today rather than a designer. I would also guess that this change would be too difficult to make now, unfortunately. - Async closures (currently available on nightly) will also make some aspects of working with async Rust easier. Async closures could borrow from their captures and I believe this feature will remove the need to specify in the bounds whether the future it returns is
Send + 'static.
Thanks to Aleksey Kladov, Benno van den Berg, Georgios Konstantopoulos, Jesse Hertz, Peter Malmgren, Senyo Simpson, Simon Rassmussen, and Will Manning for feedback on drafts of this blog post. (Of course this does not mean that they endorse or necessarily agree with the arguments presented here.)
Discuss on Reddit, Lobste.rs, or Hacker News.