Comparing full text search algorithms: BM25, TF-IDF, and Postgres
I wrote another post about Understanding the BM25 full text search algorithm and had initially included comparisons with two other algorithms. However, that post was already quite long so here are the brief comparisons between BM25, TF-IDF, and PostgreSQL's full text search.
BM25 vs TF-IDF
TF-IDF was the main model that was used prior to the development of BM25 (it was used in Lucene and Elasticsearch until 2016).
While TF-IDF also tries to use Term Frequency (TF) and the Inverse Document Frequency (IDF) to estimate the relevance of documents, BM25 introduced some key improvements:
- Saturation function for term frequency: as mentioned earlier, BM25 limits the effect of terms that are repeated very often. We care about term frequency, but only up to a point. In contrast, TF-IDF does not limit the impact of term repetition on the final score.
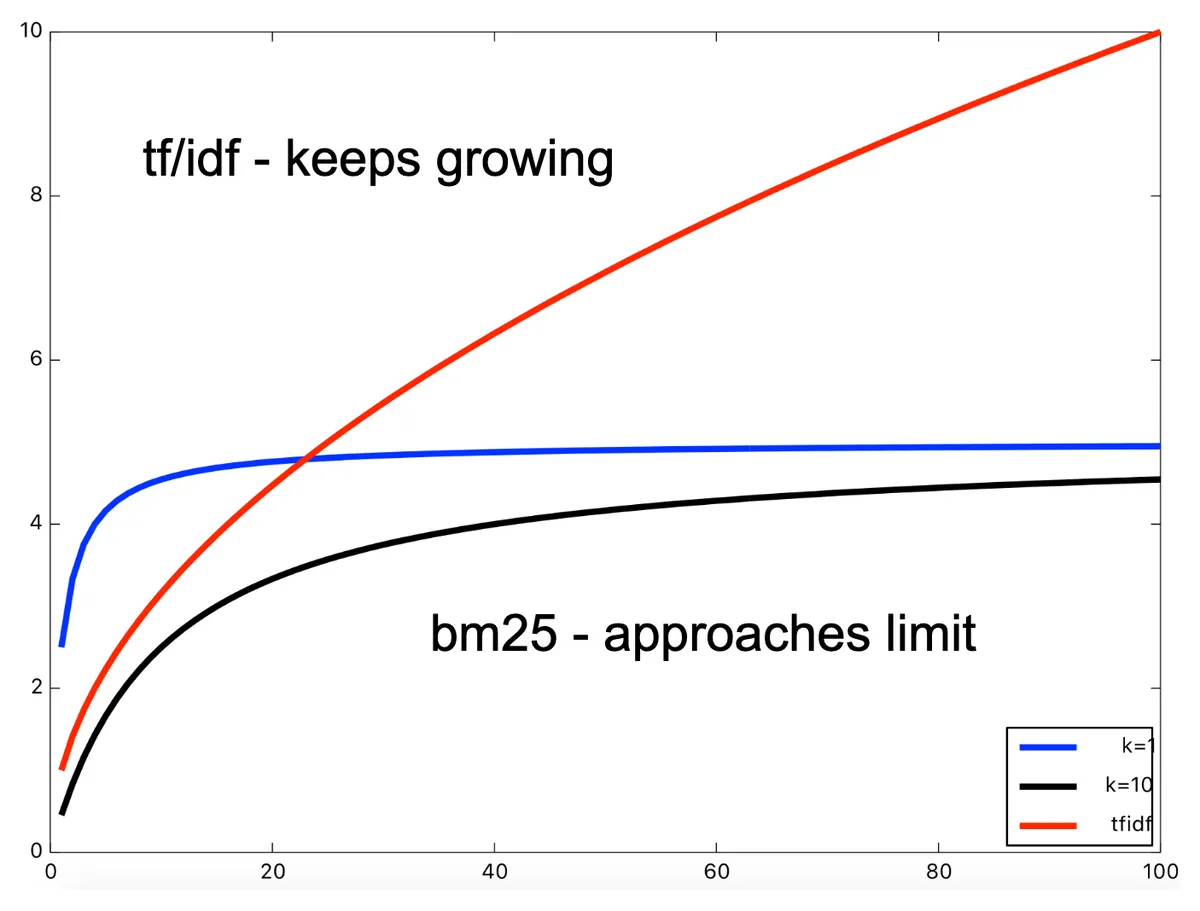
- Document length normalization: BM25 includes document length normalization to handle the fact that longer documents are likely to have the query terms repeated more, simply by virtue of being longer. TF-IDF generally does not take document length into account, which may bias the results towards longer documents.
- Smoothed Inverse Document Frequency: BM25's IDF smooths out the effect of query terms that are either very common or very rare. TF-IDF does not do this, which can lead to unstable results at both ends of the frequency spectrum.
- Tuning parameters: BM25 has the two parameters , which controls term frequency saturation, and , which controls the degree of document length normalization. TF-IDF is parameter-free, which makes it simpler but less flexible.
- Theoretical foundation: BM25 was built up from the Probabilistic Relevance Framework, which gives it a strong theoretical foundation. In contrast, TF-IDF was based on heuristics that were found to work decently well in practice.
BM25 vs PostgreSQL's full text search
Postgres' built-in full text search is simpler and less powerful than BM25. Some of the specific differences include:
- IDF vs. stopword dictionaries: BM25 uses the frequency of terms throughout the full collection of documents to determine which words are unimportant or important. In contrast, Postgres uses language-specific dictionaries of "stopwords" (for example, "the", "in", "and", etc.) to filter out unimportant terms from search queries.
- Frequency with saturation + rarity vs. frequency + position: As discussed above, BM25 uses the query term frequency with the saturation function and the term rarity (as measured by the IDF) to rank documents. Postgres uses term frequency without the saturation function. It either allows users to rank documents purely based on the term frequency (
ts_rank) or based on the term frequency and the distance between the query terms within the document (ts_rank_cd). - Document length normalization: BM25 normalizes the length of documents by comparing each document's length to the average in the full collection. By default, Postgres does not apply any length normalization. It offers some options to normalize the rank by the document length but, importantly, none of the options allow using properties of the other documents in the corpus like the average length.
As far as I understand, Postgres' built-in search results may be somewhat worse than a system using BM25, though that may not be an issue for systems already using Postgres where simplicity is more important than search quality.
It is also worth mentioning that ParadeDB has a Postgres extension called pg_bm25 (formerly called pg_search), which adds support for BM25-based ranking.
Coincidentally, just yesterday I found an article on Scour (the personalized content feed I'm building) that benchmarks ParadeDB's full text search extension against PostgreSQL's native full text search. Spoiler alert: ParadeDB's implementation of BM25-based search is much faster.